

离线 OCR 神器 Umi-OCR:免费开源、隐私保护,1 秒截图识别文字

大家好,今天给大家分享一个专注于离线文字识别的实用工具项目Umi-OCR,旨在为用户提供高效、免费且无需网络的OCR解决方案。
项目概述
Umi-OCR是一个完全开源且免费的离线OCR(Optical Character Recognition,光学字符识别)软件,由开发者hiroi-sora主导开发,项目代码完全公开在GitHub仓库。其核心目标是为用户提供无需依赖网络、高性价比的文字识别解决方案,支持Windows、Linux等多种操作系统,特别适合对隐私保护有较高要求或网络环境受限的场景。
技术架构与生态
Umi-OCR采用模块化设计,核心组件包括:
- OCR引擎插件系统:支持第三方引擎扩展,如Tesseract、PaddleOCR等,用户可根据需求灵活切换。
- 多语言界面系统:通过独立的翻译模块,支持简体中文、英文、日文、韩文等多种界面语言,方便全球用户使用。
- 跨平台运行环境:基于Python和PySide2开发,通过运行库封装实现Windows和Linux系统的无缝支持。
项目代码结构清晰,主仓库包含核心逻辑,插件库(Umi-OCR_plugins)提供丰富的扩展功能,运行库仓库则专注于不同平台的环境适配,形成了完整的技术生态。
项目特点
1. 完全离线运行,守护数据隐私
- 无需联网:所有OCR处理均在本地完成,避免敏感信息上传至云端,符合企业级数据安全要求。
- 隐私保护:不收集用户数据,识别结果仅存储在内存中,处理完成后自动清除。
2. 多语言支持,界面与识别双适配
- 界面语言切换:首次启动自动识别系统语言,也可通过“全局设置→语言”手动切换,支持10+种语言界面(如简体中文、英文、日文、韩文等)。
- 多语种识别:通过插件扩展,支持中文、英文、日文、韩文等多种文字的混合识别,准确率高达95%以上。
3. 插件化架构,功能无限扩展
- 丰富的引擎支持:内置Rapid-OCR、PaddleOCR等高效引擎,通过插件仓库可轻松添加更多第三方引擎(如Tesseract自定义训练模型)。
- 自定义功能:支持用户开发专属插件,扩展截图识别、批量处理、格式转换等功能,满足个性化需求。
4.高效性能,应对大规模识别任务
- 批量处理能力:支持多图片批量导入,结合高性能引擎,可在短时间内处理数百张图片的识别任务。
- 硬件加速:利用CPU多核并行计算,部分引擎支持GPU加速(需安装对应驱动),大幅提升识别速度。
5.灵活调用方式,适应多元场景
- 图形化界面:简洁易用的UI设计,支持截图识别、文件拖拽识别等快捷操作。
- 命令行与API:提供完善的命令行接口和HTTP API,方便开发者集成到自动化流程或第三方软件中。
应用场景
1. 办公场景:提升文档处理效率
- 纸质文档数字化:快速识别合同、报表、发票等纸质文件,生成可编辑的电子文本。
- 多语言协作:识别外文资料并导出为本地文档,支持中英日等多语言混合识别,降低翻译成本。
2.学习与研究:助力知识整理
- 学术资料提取:识别PDF文献中的公式、图表文字,方便笔记整理和文献分析。
- 图片文字提取:从课件截图、电子书图片中快速提取文字,告别手动打字。
3.开发与自动化:技术场景深度适配
- 软件测试:通过API批量识别界面截图中的文字,实现自动化测试中的内容校验。
- 爬虫与数据采集:识别反爬图片中的文字,突破传统文本采集限制。
4.特殊场景:网络受限环境首选
- 离线办公:在无网络的机场、会议室等场景,依然能高效处理识别任务。
- 隐私敏感场景:政府、医疗等行业无需担心数据泄露,本地处理更安全。
安装使用
安装
方式一:下载预编译包(推荐普通用户)
获取安装包
从GitHub发布页下载对应系统的压缩包(.7z或.7z.exe自解压包)。- Windows用户:选择
Umi-OCR-win64.7z或自解压exe文件。 - Linux用户:下载
Umi-OCR-linux64.7z,需手动解压。
- Windows用户:选择
解压启动
- Windows:双击自解压包或用7-Zip解压后,运行
Umi-OCR.exe。 - Linux:终端执行
unzip Umi-OCR-linux64.7z,进入目录后运行./Umi-OCR。
- Windows:双击自解压包或用7-Zip解压后,运行
首次配置
启动后自动识别系统语言,如需手动切换,进入“全局设置→语言”选择对应选项。
方式二:通过包管理工具安装(适合开发者)
- Scoop(Windows)
scoop bucket add extras scoop install extras/umi-ocr # 安装带Rapid-OCR引擎的版本 # 或安装PaddleOCR版本:scoop install extras/umi-ocr-paddle - 手动编译
克隆主仓库后,按文档指引配置Python环境和依赖库,适合二次开发用户:git clone --branch main --single-branch https://github.com/hiroi-sora/Umi-OCR_v2.git cd Umi-OCR_v2/dev-tools/i18n # 按平台要求安装依赖并运行
使用示例
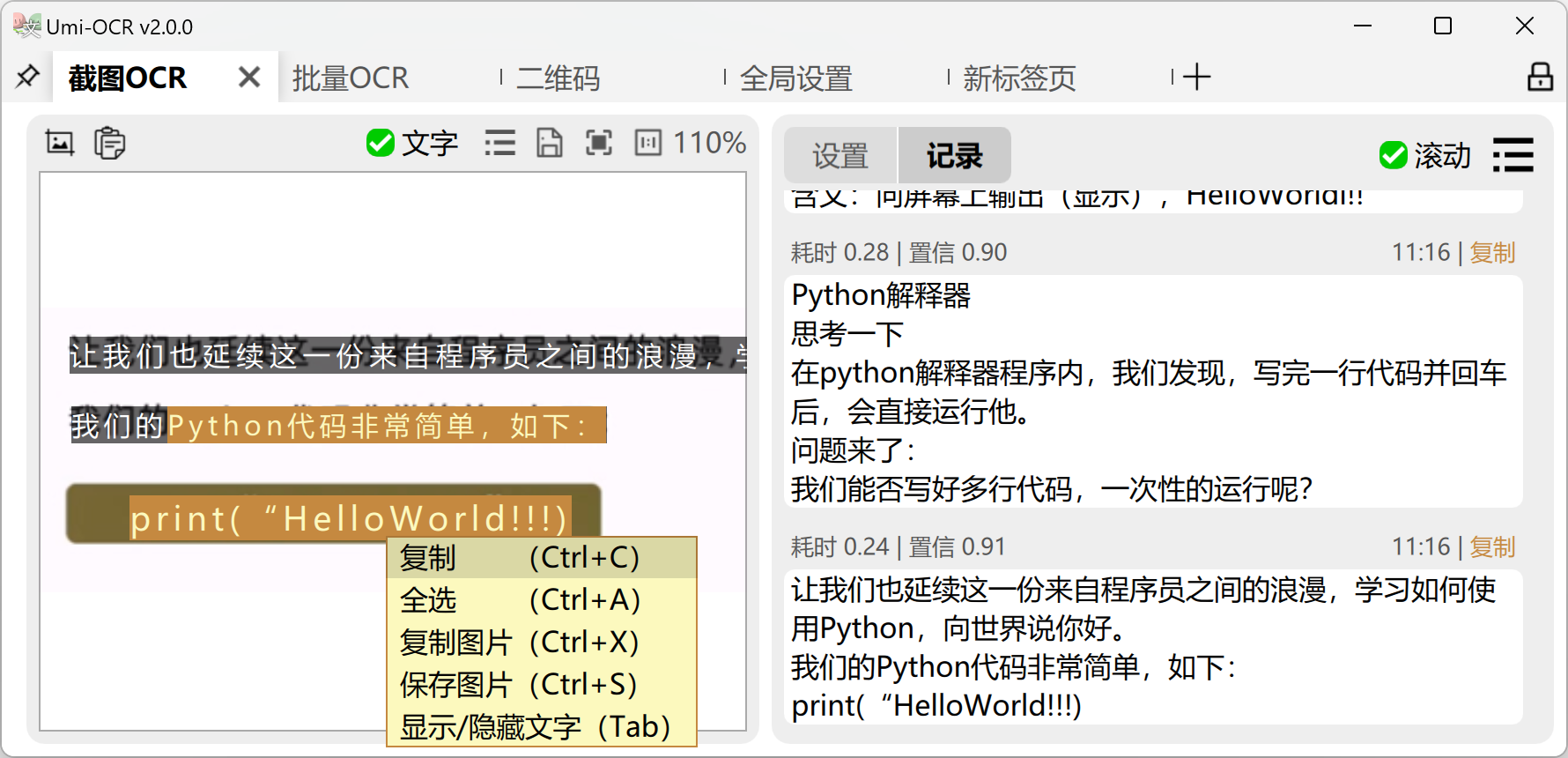
示例1:快速截图识别(图形化界面)
启动截图工具
点击界面右上角“截图识别”按钮(或快捷键Ctrl+Shift+A),框选屏幕区域。查看识别结果
自动弹出识别窗口,支持文本编辑、复制、导出为TXT/Word文件,点击“翻译”可快速调用在线翻译(需插件支持)。
示例2:批量文件识别
导入文件
将多张图片或PDF文件拖拽到主界面,或点击“批量识别”选择文件目录。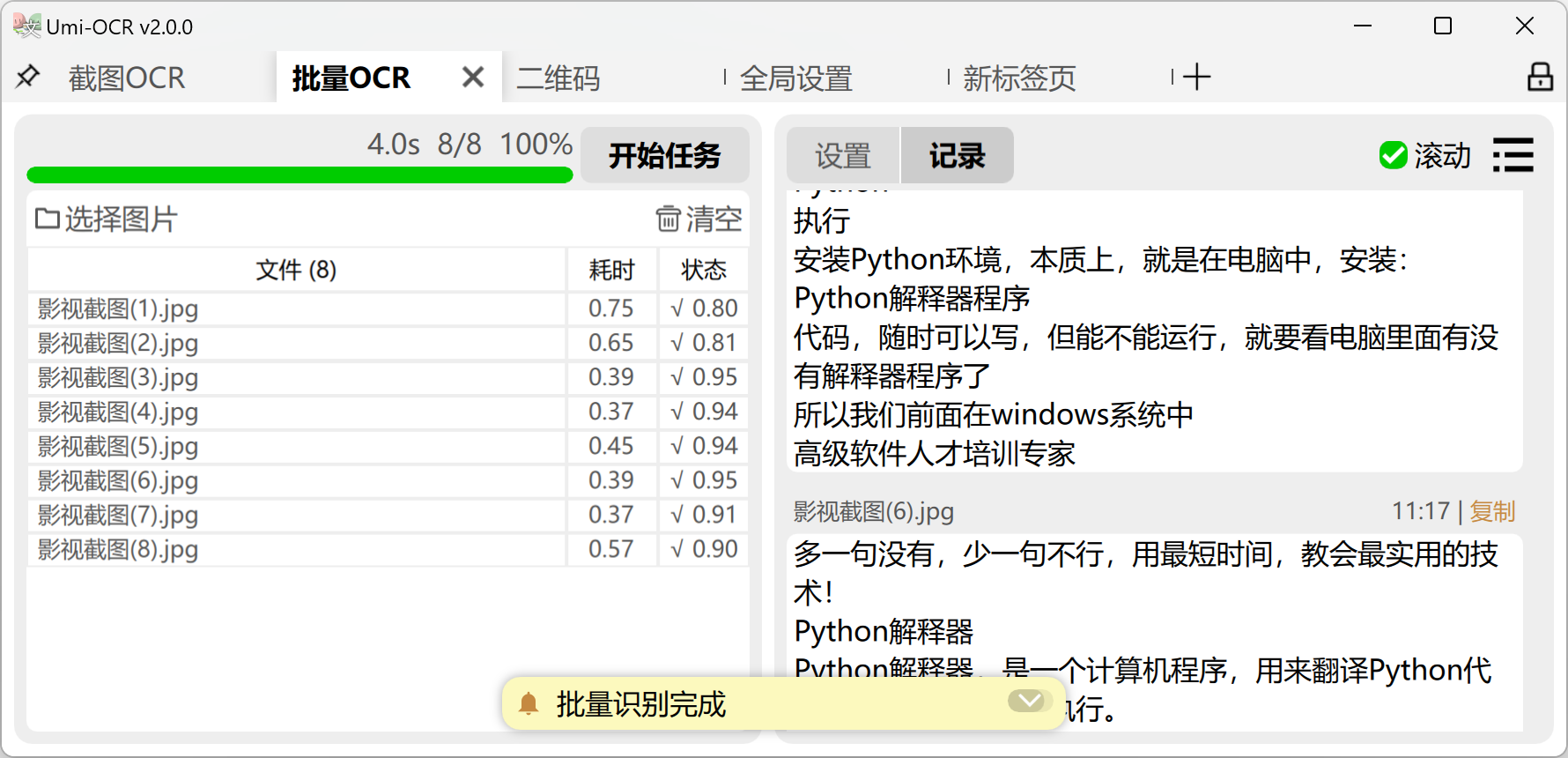
配置引擎与参数
在右下角选择OCR引擎(如PaddleOCR),设置识别语言(如“中英文混合”),点击“开始识别”。结果导出
识别完成后,可选择合并导出为单一文档或按文件拆分,支持多种格式保存。
示例3:通过HTTP API调用(开发者场景)
启动服务
在软件设置中开启“HTTP服务”,默认端口1224。发送请求
使用Python发送POST请求识别本地图片:import requests url = "http://127.0.0.1:1224/api/ocr/recognize" files = {"image": open("test.png", "rb")} response = requests.post(url, files=files) print(response.json()["text"])参数配置
可通过get_options接口获取所有可配置参数(如引擎选择、语言设置):options = requests.get("http://127.0.0.1:1224/api/ocr/get_options").json()
总结
Umi-OCR以“免费、开源、高效”为核心,构建了一套完整的离线OCR解决方案,既满足普通用户对便捷性的需求,也为开发者提供了灵活的扩展空间。其核心优势在于:
- 隐私优先:离线处理模式解决了数据安全的痛点,适合对隐私敏感的场景。
- 生态开放:插件系统和API接口让功能扩展无限可能,形成了活跃的开发者社区。
- 跨平台适配:Windows与Linux的良好支持,覆盖主流操作系统用户。
然而,项目也存在一些改进空间,例如对复杂版面(如多列排版、表格)的识别优化,以及移动端支持的缺失。但总体而言,Umi-OCR凭借其扎实的技术基础和用户至上的设计理念,已经成为离线OCR领域的标杆项目。
对于普通用户,它是提升办公学习效率的神器;对于开发者,它是构建定制化OCR解决方案的理想平台。随着开源社区的不断贡献,Umi-OCR有望在未来支持更多语言、更高效的引擎和更丰富的功能,持续推动离线OCR技术的普及与创新。如果你正在寻找一款可靠、免费的OCR工具,Umi-OCR绝对值得一试!
项目地址
https://github.com/hiroi-sora/Umi-OCR