

RAG 架构新突破!Vanna 实现自然语言到 SQL 的精准转化,支持 10 + 数据库与主流 LLM

大家好,今天给大家分享一个非常实用的开源项目——Vanna,旨在为开发者提供一个高效、灵活且安全的SQL生成解决方案。
Vanna是一个基于Python的检索增强生成(RAG)框架,专注于将自然语言问题转化为SQL查询,同时支持与多种数据库、大型语言模型(LLM)和向量数据库的集成。
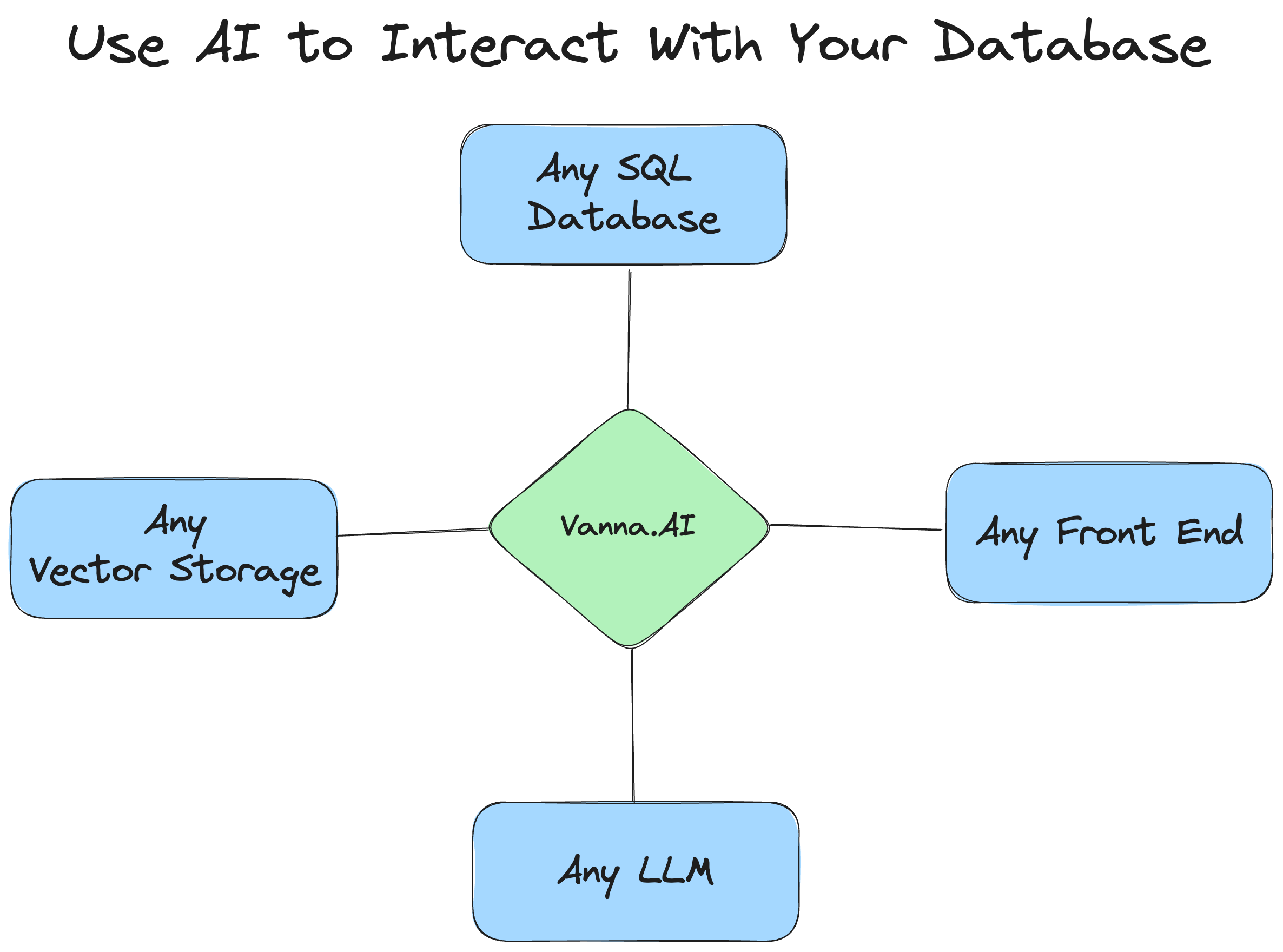
项目概述
Vanna的核心目标是降低数据查询的技术门槛,让用户无需精通SQL语法,只需通过自然语言提问,即可自动生成准确的SQL语句。它结合了RAG技术,通过向量数据库存储和检索上下文信息,结合LLM的生成能力,实现对复杂业务问题的理解和SQL生成。项目架构设计灵活,支持自定义扩展,允许用户替换底层的LLM和向量数据库,满足不同场景下的技术需求。
项目特点
1. 高准确性与自学习能力
- 数据驱动优化:通过用户提供的训练数据(如历史SQL-问题对、DDL定义),Vanna能针对性地优化生成逻辑,尤其在复杂数据集上表现优异。例如,用户可通过
vn.train()方法注入自定义SQL案例,逐步提升模型对特定业务场景的理解。 - 上下文感知:结合向量数据库存储的历史对话和Schema信息,生成SQL时能准确引用表结构、字段别名等细节,减少语义歧义。
2. 安全与隐私保护
- 本地化执行:用户的数据库内容始终在本地环境执行,LLM仅接收脱敏后的元数据(如表名、字段名),敏感数据不会泄露到外部服务。
- 权限控制:支持通过配置文件或环境变量管理API密钥,确保对外部服务(如LLM接口)的安全访问。
3. 多技术栈兼容性
- 数据库支持:兼容PostgreSQL、Snowflake、BigQuery、DuckDB等主流SQL数据库,通过SQLAlchemy接口实现统一连接,用户只需配置连接参数即可切换数据库。
- LLM与向量数据库扩展:基于
VannaBase抽象类,开发者可轻松集成自定义LLM(如Hugging Face模型)或向量数据库(如FAISS),示例代码展示了如何组合ChromaDB_VectorStore和OpenAI_Chat实现个性化配置。
4. 灵活的用户界面适配
- 多终端支持:除基础API外,Vanna提供Jupyter Notebook、Streamlit、Flask、Slack等前端模板,方便快速构建数据查询工具。例如,在Jupyter中可直接调用
vn.ask()方法,实时显示SQL结果和图表。 - 可视化能力:集成Plotly等库,支持根据查询结果自动生成可视化图表,提升数据分析效率。
5. 开发者友好的生态
- 简明的API设计:核心接口如
generate_sql()、ask()封装了复杂逻辑,用户无需关心底层RAG流程,只需传入问题和配置即可获取结果。 - 详细的错误处理:针对API密钥缺失、数据库连接失败等场景提供清晰的异常提示(如
OTPCodeError、ValidationError),降低调试成本。
技术架构与关键组件
核心模块:
- LLM集成层:支持OpenAI、Anthropic、Gemini、ZhipuAI、Qianwen等多种LLM,通过统一接口处理提示词生成和响应解析。
- 向量数据库层:默认支持ChromaDB,可扩展至其他向量数据库,用于存储和检索历史对话、数据库Schema、训练数据等上下文信息。
- SQL生成引擎:基于训练数据和实时输入,生成符合语法规范的SQL语句,并支持结果解析和可视化。
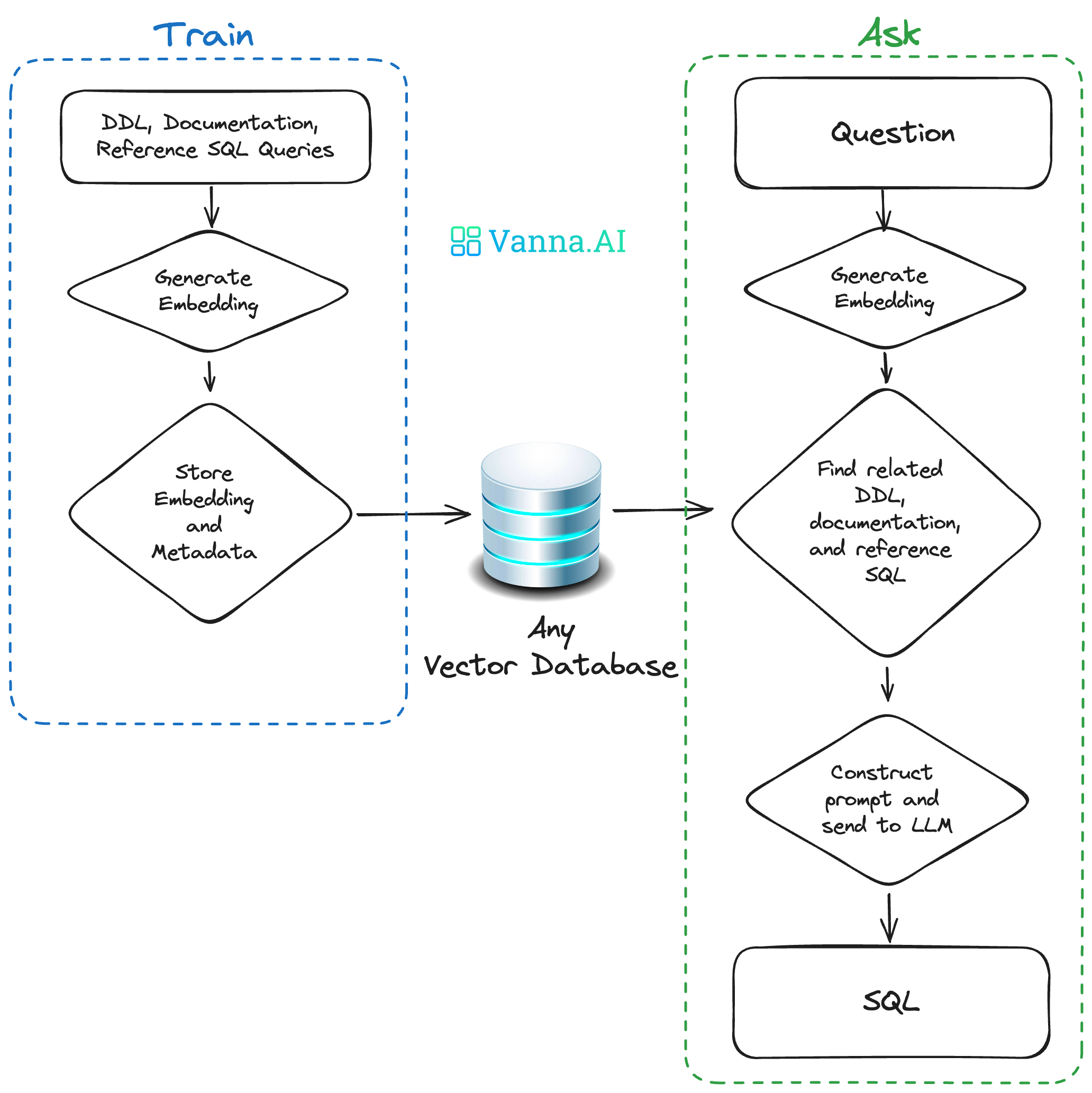
数据流程:
用户输入自然语言问题→Vanna检索相关上下文(如历史对话、DDL定义、训练数据)→LLM生成SQL候选→语法校验和优化→执行SQL并返回结果,同时支持自动训练以提升后续准确性。
应用场景
1. 企业数据分析与BI工具
- 场景描述:企业员工通过自然语言查询业务数据(如“上月各地区销售额排名”),Vanna自动生成SQL并连接到数据仓库,返回结果并可视化。
- 价值:降低非技术人员的使用门槛,减少数据团队的重复查询工作,加速决策过程。
2. 教育与培训领域
- 场景描述:教学平台利用Vanna构建SQL练习工具,学生输入自然语言问题,系统生成SQL并校验正确性,同时提供解释和优化建议。
- 价值:帮助初学者通过自然语言理解SQL逻辑,提升学习效率。
3. 数据中台与低代码平台
- 场景描述:作为底层引擎集成到低代码平台中,用户通过拖拽式界面配置问题模板,Vanna自动生成对应的SQL,支持数据抽取、清洗等操作。
- 价值:简化数据管道开发,提升平台的智能化水平。
4. 实时数据交互工具
- 场景描述:在Slack或企业微信中部署Vanna机器人,用户通过聊天提问实时获取数据库数据(如“当前库存预警的产品有哪些”),机器人返回SQL结果和图表。
- 价值:实现即时数据查询,增强团队协作效率。
5. 科研与数据分析协作
- 场景描述:研究团队在Jupyter Notebook中使用Vanna快速验证数据假设,通过
auto_train功能积累领域特定的查询案例,提升跨成员协作的一致性。 - 价值:减少重复编码,聚焦数据分析本身。
安装使用
安装
1. 基础安装
通过PyPI快速安装核心包:
pip install vanna2. 可选依赖(根据使用场景安装)
- 数据库驱动:
- PostgreSQL:
pip install vanna[postgres] - Snowflake:
pip install vanna[snowflake] - BigQuery:
pip install vanna[bigquery]
- PostgreSQL:
- 向量数据库:
- ChromaDB(默认):无需额外安装,如需其他向量数据库(如FAISS),需单独安装对应库。
- LLM支持:
- OpenAI:自动安装
openai库(需配置API密钥)。 - ZhipuAI/Qianwen:手动安装
zhipuai或相关SDK,并在配置中指定API密钥。
- OpenAI:自动安装
3. 环境配置
- API密钥:通过
config参数或环境变量设置LLM和Vanna服务的API密钥,例如:config = {"api_key": "your_vanna_api_key", "model": "gpt-4"} vn = VannaDefault(model="gpt-4", api_key="your_vanna_api_key") - 数据库连接:使用
connect_to_*方法配置数据库连接参数,如connect_to_snowflake(account="xxx", username="xxx", password="xxx")。
使用示例
1. 基础流程:自然语言生成SQL
# 导入核心类(以OpenAI和ChromaDB为例)
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
# 配置API密钥和模型
config = {
"api_key": "your_openai_api_key",
"model": "gpt-3.5-turbo",
"path": "./chroma_db" # 向量数据库存储路径
}
vn = MyVanna(config=config)
# 定义SQL执行函数(示例:使用pandas连接数据库)
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine("postgresql://user:password@host:port/dbname")
vn.run_sql = lambda sql: pd.read_sql(sql, engine)
# 提问并获取结果
question = "查询2023年销售额超过100万的客户名单"
sql, df, fig, followups = vn.ask(question, auto_train=True)
print("生成的SQL:", sql)
print("查询结果:", df.head())2. 高级功能:自定义训练数据
# 添加手动训练的SQL-问题对
training_data = [
{"question": "上个月的订单总数", "sql": "SELECT COUNT(*) FROM orders WHERE order_date >= '2023-11-01'"}
]
vn.add_sql(question=training_data[0]["question"], sql=training_data[0]["sql"])
# 获取训练计划并调整
plan = vn.get_training_plan()
plan.remove_item("Train on SQL: 上个月的订单总数") # 移除不需要的训练项
vn.train(plan=plan) # 提交训练计划3. 多LLM支持:使用ZhipuAI模型
from vanna.ZhipuAI.ZhipuAI_Chat import ZhipuAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyZhipuVanna(ChromaDB_VectorStore, ZhipuAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
ZhipuAI_Chat.__init__(self, config=config)
config = {
"api_key": "your_zhipu_api_key",
"model": "glm-4",
"embedding_function": ZhipuAIEmbeddingFunction(config=config) # 配置向量生成函数
}
vn = MyZhipuVanna(config=config)总结
1. 项目优势与竞争力
Vanna凭借“高准确性+强扩展性+安全隐私”的核心优势,在SQL生成领域形成独特定位。与传统工具相比,它无需复杂的模型训练流程,通过即插即用的组件化设计,让用户快速集成到现有数据架构中。同时,对多种LLM和数据库的支持,使其适配性远超单一解决方案,尤其适合企业级复杂数据环境。
2. 适用人群与场景建议
- 推荐人群:数据分析师、Python开发者、企业BI团队、教育工作者。
- 最佳实践:
- 从小型场景入手,如Jupyter中的数据探索,逐步积累训练数据;
- 利用社区提供的前端模板(如Streamlit)快速构建用户界面;
- 结合向量数据库存储业务特定的Schema和历史查询,提升生成准确性。
3. 未来展望
随着RAG技术的普及和LLM能力的提升,Vanna有望在以下方向进一步扩展:
- 多模态支持:结合表格、图表等可视化元素生成更复杂的分析报告;
- 实时数据流处理:支持流式数据查询和动态更新训练数据;
- 低代码生态集成:成为数据中台和AI工具链中的核心组件,推动“数据即服务”的落地。
总之,Vanna是一个兼具实用性和创新性的开源项目,它通过技术整合降低了数据交互的门槛,让自然语言驱动的SQL生成成为可能。无论你是想提升数据分析效率,还是构建智能数据工具,Vanna都值得一试。